
La société responsable du programme DALL-E propose un système de reconnaissance vocale open-source destiné aux chercheurs et aux développeurs. Whisper offre des fonctions de transcription, mais aussi de traduction en anglais.
OpenAI, fondée entre autres par Elon Musk, est une société spécialisée dans l’artificielle. Elle est connue en particulier pour son système DALL-E qui permet de concevoir des œuvres à partir de descriptions. Ce système permet aussi d’ajouter des éléments autour d’une image existante. Mais OpenAI vient de communiquer sur un autre domaine : la reconnaissance vocale. La société lance un programme open-source baptisé Whisper qui permet de transformer de la voix en texte pour l’anglais, mais aussi pour d’autres langues. Associé à des modèles, le programme offre des fonctions de transcription, mais aussi de traduction en anglais. Il doit aussi pouvoir ne pas tenir compte de bruits de fond, par exemple de la musique, quand la personne ne parle pas. Enfin, il est capable de détecter automatiquement la langue parlée.
L’audio en entrée est découpé en blocs de 30 secondes, qui sont convertis en spectrogrammes. L’architecture de Whisper fonctionne sur un principe simple d’encodage/décodage pour chaque bloc :
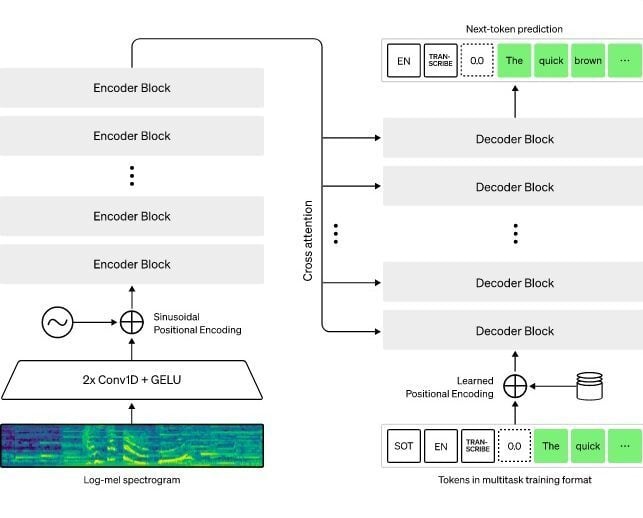
Pour cela, OpenAI a entrainé un réseau neuronal avec 680 000 heures de données. Sur cet ensemble, 438 000 heures correspondent à de l’anglais avec une transcription en anglais. La portion de 126 000 heures correspond à d’autres langues avec leur traduction en anglais, tandis que 117 000 heures concernent une autre langue que l’anglais avec la transcription native correspondante. L’apprentissage a été effectué avec un total de 99 langues. Les résultats montrent que la performance de la transcription de Whisper est meilleure quand le réseau neuronal a bénéficié de plus d’heures d’apprentissage.
Un système plus robuste dans certains cas
Il existe déjà de nombreux systèmes de reconnaissance vocale automatique (ASR en anglais) sur le marché, par exemple ceux employés par Apple, Microsoft, Amazon et Google. Mais selon les études d’OpenAI, les modèles utilisés dans Whisper montrent une meilleure robustesse pour le traitement des accents, des bruits de fond et des jargons techniques.
Car le problème de la reconnaissance vocale est le manque de diversité linguistique lors de la phase d’apprentissage. Ainsi, une étude de l’Université de Stanford, réalisée au printemps 2019 sur les systèmes d’Amazon, Apple, Google, IBM et Microsoft, révèle que le taux d’erreur est quasiment deux fois plus élevé pour les utilisateurs noirs que pour les utilisateurs blancs : 41 erreurs en moyenne pour chaque centaine de mots, contre 21 erreurs. Chez les femmes, le nombre d’erreurs est en moyenne de 30 contre 17.
Toutefois, le système d’OpenAI souffre de limitations : il est surtout efficace en anglais et peut inclure des mots dans les transcriptions qui n’ont pas été prononcés par l’utilisateur. Cela provient de son approche qui tente à la fois de transcrire l’audio, mais aussi de prédire quelle sera le prochain mot dans une phrase. OpenAI insiste aussi sur des écarts de performances selon les différents accents et dialectes.
Whisper est disponible sur Github pour les chercheurs en intelligence artificielle, mais aussi pour les développeurs qui désirent utiliser le système dans leurs programmes, moyennant un affinement des réglages.
Source :
TechCruch